Many people who have tried OpenCV’s traincascade tool know about a very disturbing error which (at least at the moment) seems to have no good solution, but nevertheless this issue has a solution (even if not convenient) so we need to stick to what we have at hand. My Cascade Trainer GUI app which also uses OpenCV as the underlying framework is also seen to produce this error with many users so I decided to discuss this and share my solution with you all, but please make sure you put your comment below if you’ve got any questions or better suggestions. So, let’s get down to it.
First of all, here’s the actual monster itself, the error that makes me want to smash my computer’s screen after hours of training time:
OpenCV Error : Bad argument(Can not get new positive sample.The most possible reason is insufficient count of samples in given vec - file.) in CvCascadeImageReader::PosReader::get, file \path_to_opencv\apps\traincascade\imagestorage.cpp, line X
With some older versions of OpenCV the error message (assert) might be even different but at the moment and with OpenCV 3.2.0 this is more or less the error message that you’ll see.
Next you are probably asking: what’s the explanation for this error? Why is it happening? And the answer is “Good Question”, and just that.
Well there is the official discussion in this page but what it’s basically saying is (I’m quoting one of OpenCV people, see this for more info):
-numPose is a samples count that is used to train each stage. Some already used samples can be filtered by each previous stage (ie recognized as background), but no more than (1 - minHitRate) * numPose on each stage. So vec-file has to contain >= (numPose + (numStages-1) * (1 - minHitRate) * numPose) + S, where S is a count of samples from vec-file that can be recognized as background right away. I hope it can help you to create vec-file of correct size and chose right numPos value.Well I assume a lot of you are confused, but fear not, because we all are. Basically what they are saying is that you need to have good samples with a low “S” number but that’s not the answer you’d expect, right? You’d like a concrete solution, like me, but unfortunately it’s not that simple for now. Next comes what I usually do besides making sure I have a “Good Sample Set”.
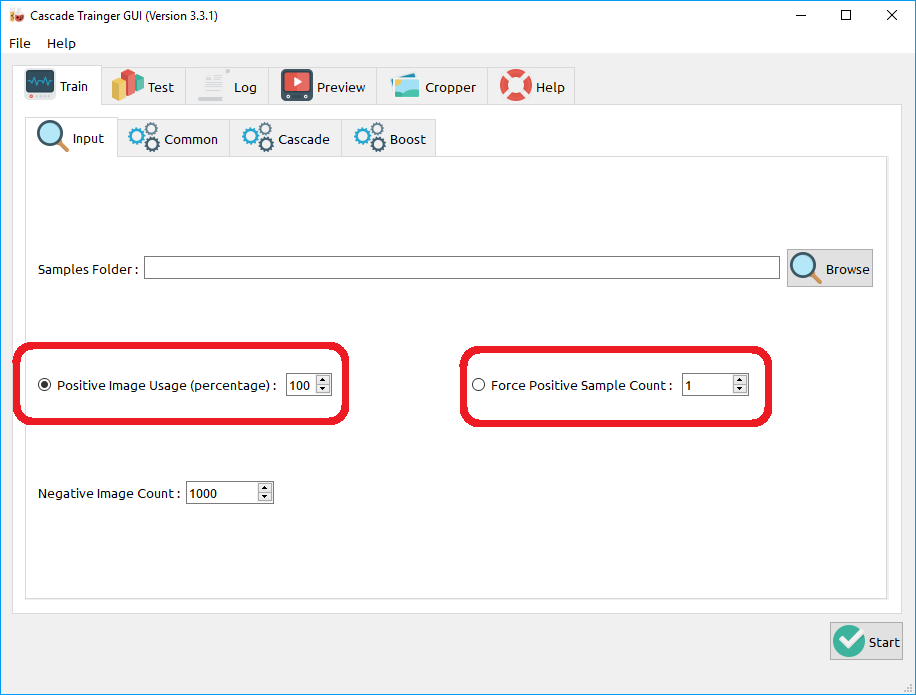
What do we need to do, you’ll ask if you’re still not disappointed enough. Well I’ve added a feature to Cascade Trainer GUI app to simplify this but if you are insisting on using opencv_traincascade then the answer is also more or less lies here. Just make sure you use a percentage lower than 100% or force a Positive Sample Count which is actually lower than your actual number of positive samples. If you get the same error yet again, then try entering even a lower percentage or lower positive sample count. I’m afraid at the moment there’s no other way but to try lowering the number until it works. Screenshot below shows where you need to set what I just mentioned in the Cascade Trainer GUI app:

Obviously if you have a lot of samples (and I mean a lot) then you are safe with entering some 90% or 80% but it becomes a real pain if your sample count is limited. But anyway that’s it for the moment. Share your comments with me please, if you’ve got any.
I can’t help but notice something. No matter what I do with the settings I can’t get it to train more than 168 positive Images. Setting the percentage gets it right if you can get your positive images down below 168. Might not be the same for everyone else but that’s what I am seeing.
Can we make the application use GPU instead of cpu for training?
Unfortunately not at the moment. However, this version uses Intel TBB to speed things up a bit more than default OpenCV traincascade.
I am getting an error “Image can not be renamed , still in use”. I tried everything but still couldn’t solve this error. Help me out
Make sure your images are not in a folder that might require Admin permissions. This is simply related to access issues with the image.
Solved this by renaming all pictures (just numbers).
Maybe it got problem with special characters.
Thanks for sharing this Mario.
Sure, used this Python 3 snippet:
# You have to create a p2 Folder, where the renamed snippets will be saved
import cv2
import os
import numpy as np
PATH=# PATH TO Folder p
pfad=os.listdir(PATH)
x=0
for item in pfad:
try:
x+=1
img = cv2.imdecode(np.fromfile(PATH+item, dtype=np.uint8), cv2.IMREAD_UNCHANGED)
cv2.imwrite(PATH+’\n2\\’+str(x)+’.png’,img)
except:
print(item)
didn’t help to rename the files, the error stull occurs.
What error are you getting?
Hey/
It`s still showing me the same error even though i deleted pictures with bad quality and chose pos sample count as 1
What error?
Bad argument(Can not get new positive sample.The most possible reason is insufficient count of samples in given vec – file.)
I don’t have anything more to offer. Please read this tutorial again. How do you decide “bad quality” by the way? This is an algorithm we’re talking about. Just try whatever is mentioned in the tutorial, a bit more.
hey i am getting the same error. Have you solved it ?
When i am training cascade it is taking long time so in middle of the process it’s been stuck without any process going, so i tried to stop and restart the process but after clicking cancel i thought of denying and clicked “No” and process started itself from where it has stopped. What should i assume whether it is still in working stage or not ?
Depending on your computer specs, it can take a long time to train a classifier.
Yes it is still in progress if you clicked No.
Your software is a nice piece, making easy for novice like me to train a model.
It works for me most of the time with 85% positive.
I have a set of a 15k positive samples.
But that doesn’t help to increase the %
I was very please to learn about the negative count taken in random
Is it also the case for positive images among the total set?
Train dataset for temp stage can not be filled. Branch training terminated.
Cascade classifier can’t be trained. Check the used training parameters.
what does this error mean?
This is usually caused by insufficient or low quality training data samples, especially positive samples.
What is the positive sample count value that you have used?
Did you try the solution in this post?
If you’re interested, check out the source codes and look for the error there:
https://github.com/opencv/opencv/blob/3.4.6/apps/traincascade/cascadeclassifier.cpp
Just want to ask. I always got this error
“Required leaf false alarm rate achieved. Branch training terminated.”
What could be the reason it happened?
See if this helps:
http://amin-ahmadi.com/2019/05/01/cascade-classifier-training-known-issues-and-workarounds/
Oh okay. Thank you for the reply. Another problem I face is it unable to detect the object that I has trained. Even it complete, it train in such a short time resulted in so poor accuracy. I even put al lot of positive and negative. Any reason about this problem?
How many number of samples? What parameters did you change and what were their values?
RGB color space not permitted on grayscale PNG and I have positive in RGB and negative of Grayscale should I convert the neg to RGB or positive to grayscale?
Not sure what you mean by “RGB color space not permitted on grayscale PNG”, nevertheless you don’t need to convert your images to grayscale for training a classifier.
I had this issue with positive images when it got to image 169, it quit out with this error.
I went into the positive images sorting them by name order and found image 169. This image was very generic and didn’t have a lot of features to stand out, so I could see why it could be mistake for background.
I moved that one image into a temp folder and restarted the Cascade GUI again and it went through fine.
If you drop down the percentage of positive images used to below the number of the one that causes the issue, you’ll miss out on all the positive images you’ve worked hard to capture.
Pulling out the image that causes the problem will leave you with all the rest of your positive images to work with, not a much smaller subset.
Thanks for sharing your experience, although you should note that it is not always easy to find which images are “generic and don’t have a lot of features to stand out”.
there is a simple way enter the exact value in force sample count
I guess you mean the exact number of positive samples when you say “exact value”?!
Unfortunately that won’t always work as expected and it’s totally based on the dataset.
What about Negative image count ?
is it the total number of Negative images we have ?
let suppose i have 10000 negative images do i need to set the value of Negative image count to 10000?
Negative images are different from positive images. They are bigger images (i.e. complete background images) and the actual negative samples are randomly extracted from them. This means, for example, you can have 50 (huge) background images and enter 10000 as the negative sample count.